Abstract
Reinforcement Learning (RL) has made significant strides in complex tasks but struggles in multi-task
settings with different embodiments. World model methods offer scalability by learning a simulation of the
environment but often rely on inefficient gradient-free optimization methods for policy extraction. In
contrast, gradient-based methods exhibit lower variance but fail to handle discontinuities. Our work reveals
that well-regularized world models can generate smoother optimization landscapes than the actual dynamics,
facilitating more effective first-order optimization. We introduce Policy learning with multi-task World
Models (PWM), a novel model-based RL algorithm for continuous control. Initially, the world model is
pre-trained on offline data, and then policies are extracted from it using first-order optimization in less
than 10 minutes per task. PWM effectively solves tasks with up to 152 action dimensions and outperforms
methods that use ground-truth dynamics. Additionally, PWM scales to an 80-task setting, achieving up to 27\%
higher rewards than existing baselines without relying on costly online planning.
Video
Method overview
We introduce Policy learning with multi-task World Models (PWM), a novel Model-Based RL (MBRL) algorithm
and framework aimed at deriving effective continuous control policies from large, multi-task world
models. We utilize pre-trained TD-MPC2 world models to efficiently learn control policies with first-order
gradients in < 10m per task. Our empirical evaluations on complex locomotion tasks indicate that PWM not
only achieves higher reward than baselines but also outperforms methods that use ground-truth
simulation dynamics.
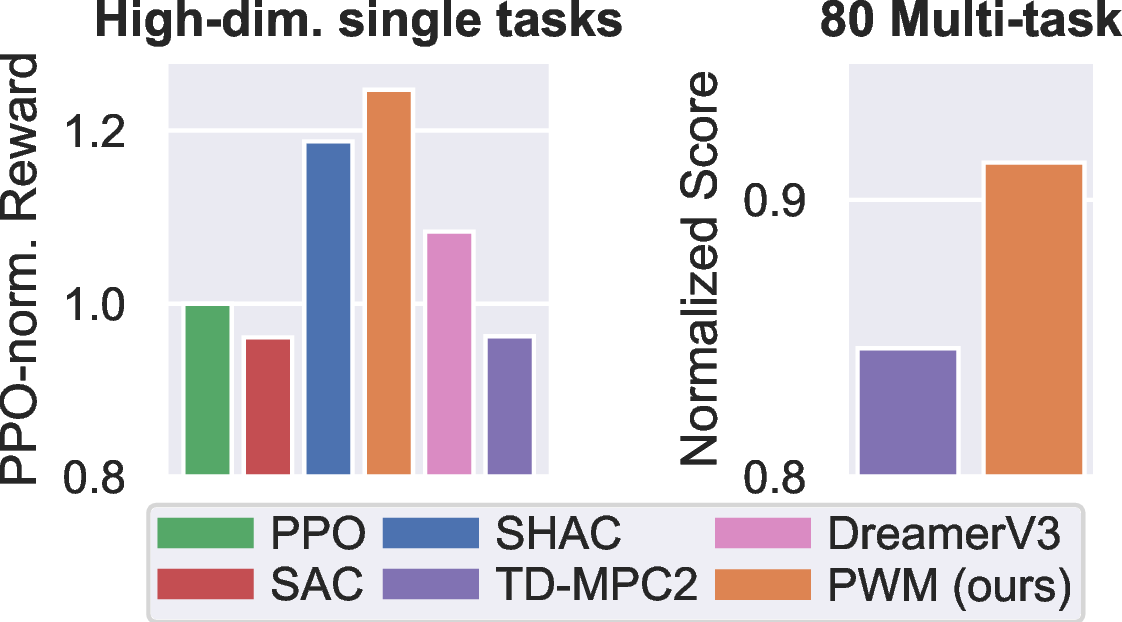
We evaluate PWM on high-dimensional continuous control tasks (left figure) and find that it not only
outperforms model-free baselines SAC and PPO but also achieves higher rewards than SHAC, a method using the
dynamics and reward function of the simulator directly. In an 80-task setting (right figure) using a
large 48M-parameter world model, PWM is able to consistently outperform TD-MPC2, an MBRL method that uses
the same world model, without the need for online planning.
Single-task results
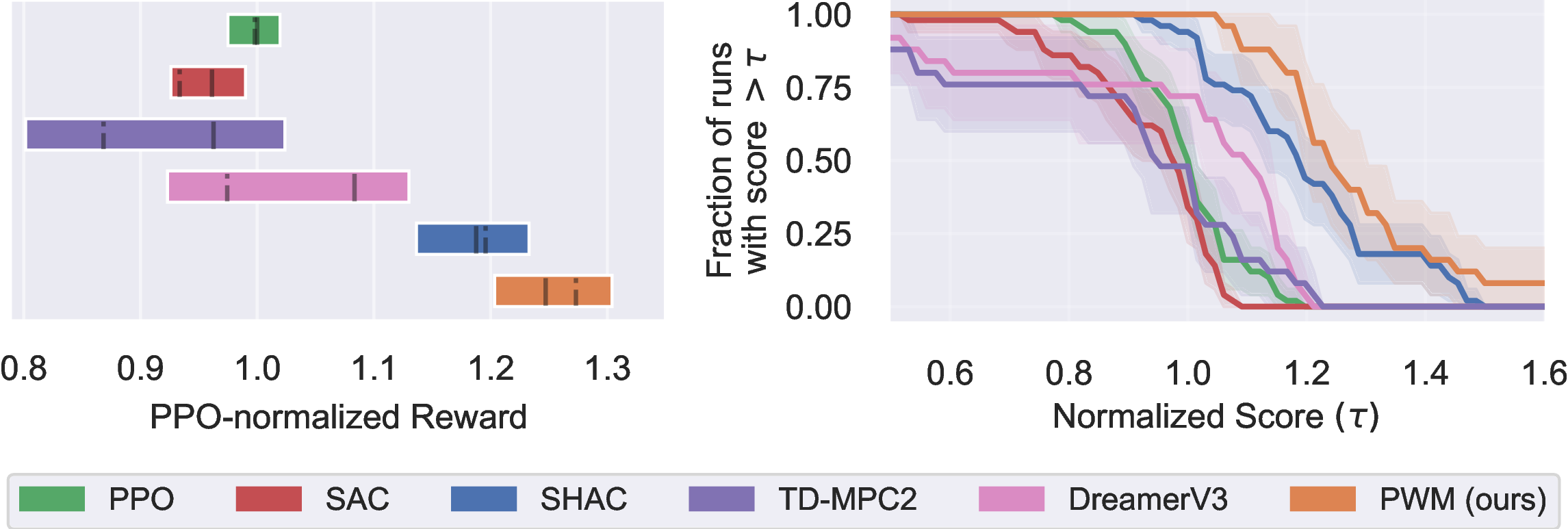
The figure shows 50% IQM with solid lines, mean with dashed lines, and 95% CI over all 5 tasks
and 5 random seeds. PWM is able to achieve a higher reward than model-free baselines PPO and
SAC, TD-MPC2, which uses the same world model as PWM and SHAC which uses the ground-truth
dynamics and reward functions of the simulator. These results indicate that well-regularized
world models can smooth out the optimization landscape, allowing for better first-order gradient
optimization.
Multi-task results
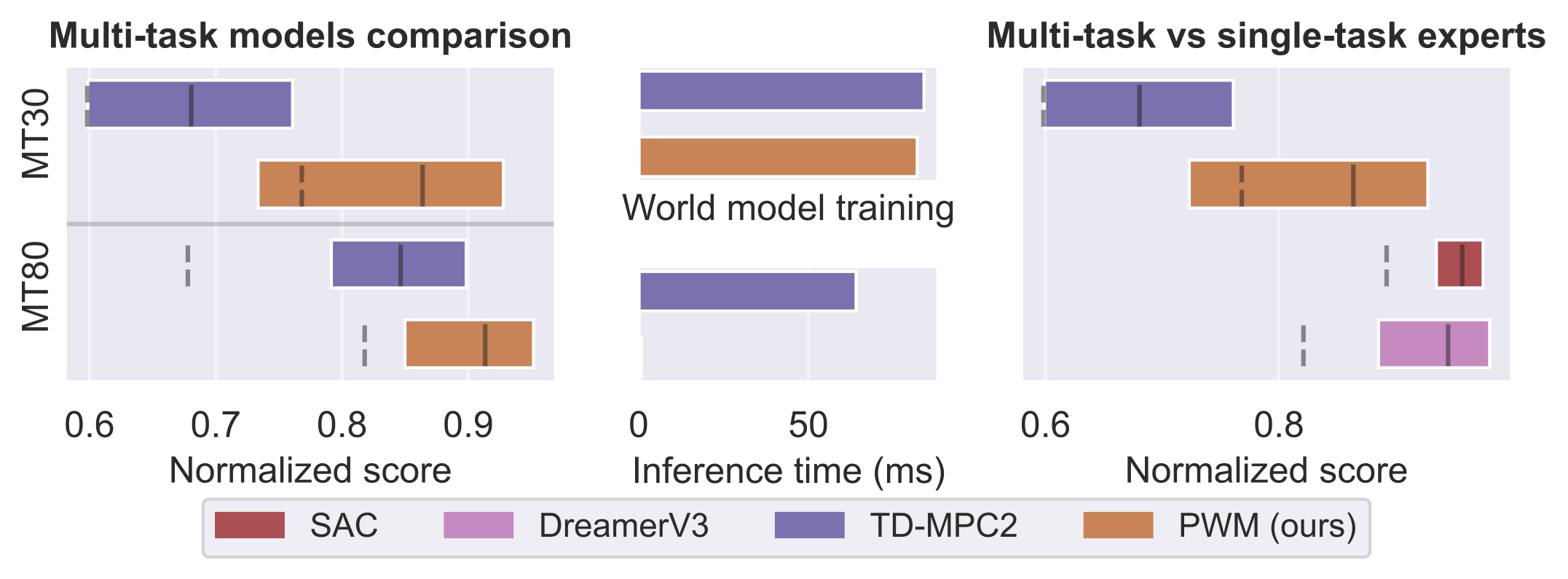
The figure shows the performance of PWM and TD-MPC2 on 30 and 80 multi-task benchmarks with
results over 10 random seeds. PWM is able to outperform TD-MPC2 while using the same world model
without any form of online planning, making it the more scalable approach to large world models.
The right figure compares PWM, a multi-task policy, with single-task experts SAC and DreamerV3.
It is impressive that PWM is able to match their performance while being multi-task and only
trained on offline data.
Citation
@misc{georgiev2024pwm,
title={PWM: Policy Learning with Multi-task World Models},
author={Georgiev, Ignat and Giridhar, Varun and Hansen, Nicklas and Garg, Animesh},
eprint={2407.02466},
archivePrefix={arXiv},
primaryClass={cs.LG},
year={2024}
}